Delta Lake Blogs
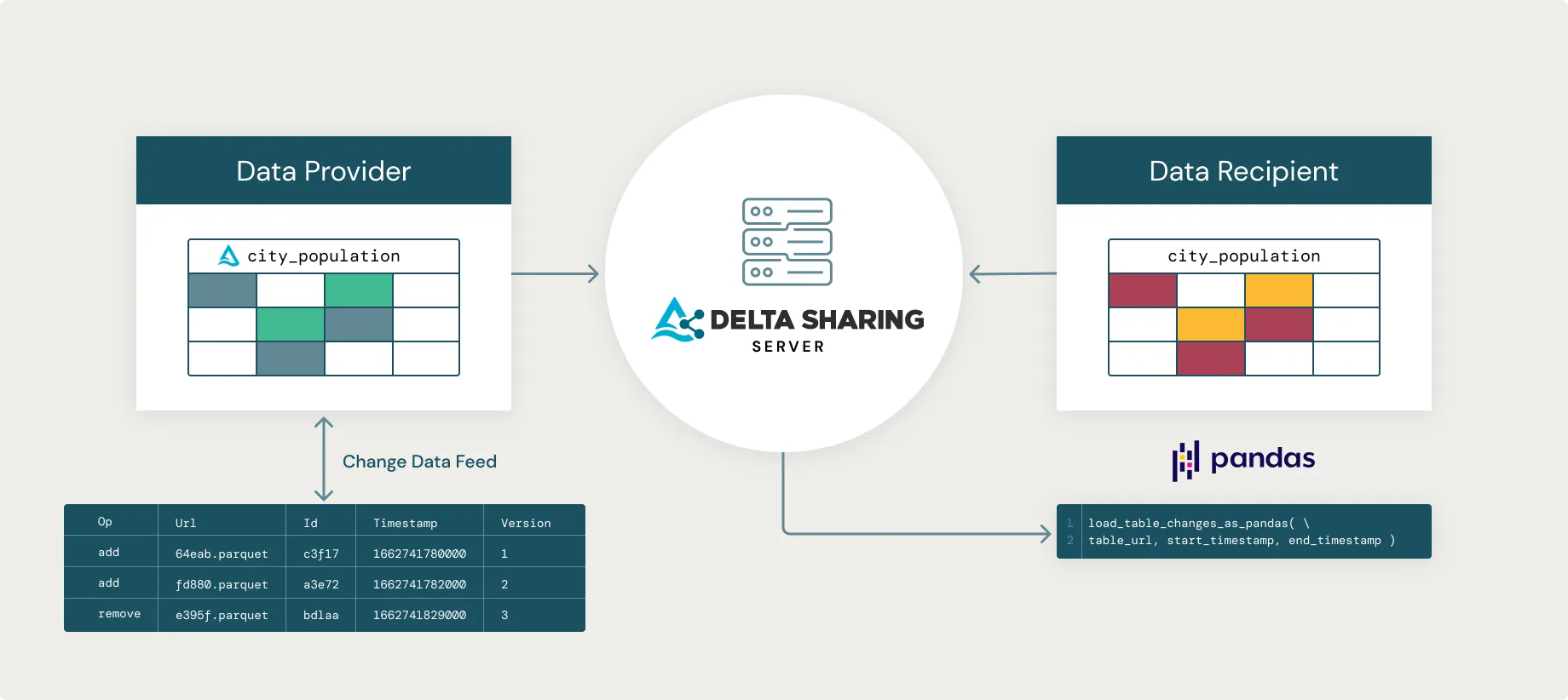
Sharing a Delta Table’s Change Data Feed with Delta Sharing 0.5.0
By Will Girten
We are excited to announce the release of Delta Sharing 0.5.0.
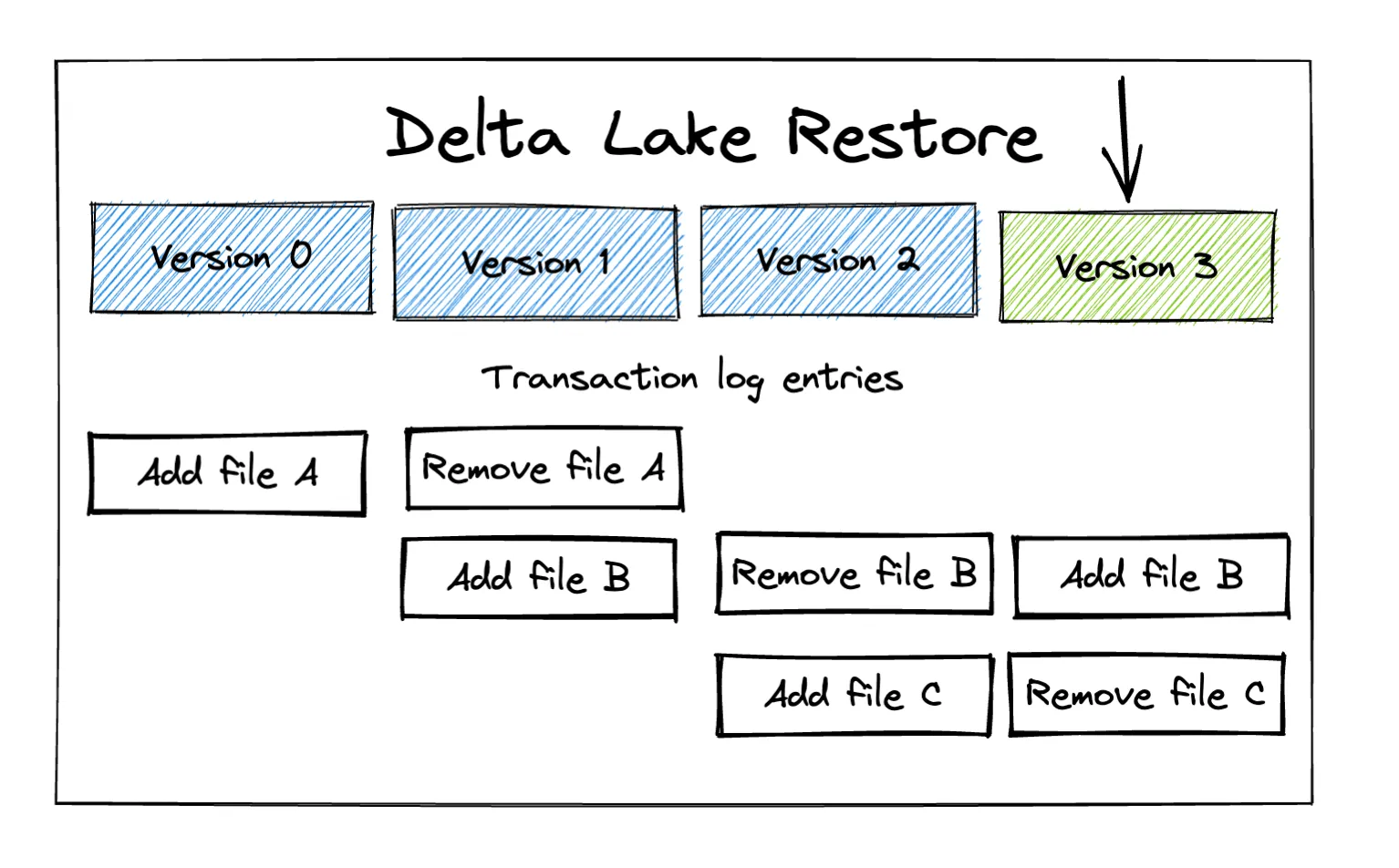
How to Rollback a Delta Lake Table to a Previous Version with Restore
This post shows you how to rollback Delta Lake tables to previous versions with restore.

Converting from Parquet to Delta Lake
This post shows how to convert a Parquet table to a Delta Lake.
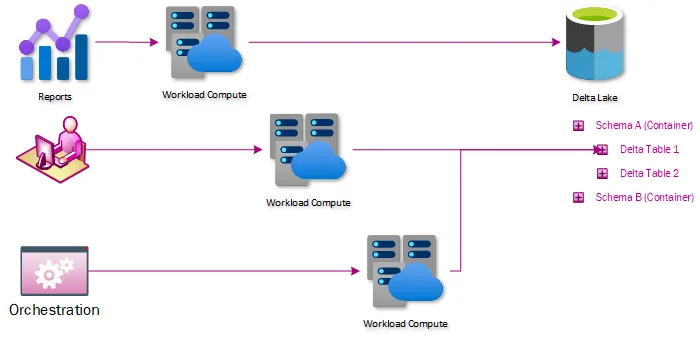
Why we migrated to a Data Lakehouse on Delta Lake for T-Mobile Data Science and Analytics Team
By Robert Thompson , Geoff Freeman
In this post, we will discuss the how and why we migrated from databases and data lakes to a data lakehouse on Delta Lake. Our lakehouse architecture allows reading and writing of data without blocking and scales out linearly. Business partners can easily adopt advanced analytics and derive new insights. These new insights promote innovation across disparate workstreams and solidify the decentralized approach to analytics taken by T-Mobile.
How to drop columns from a Delta Lake table
This post shows you two ways to drop columns from Delta Lake tables.
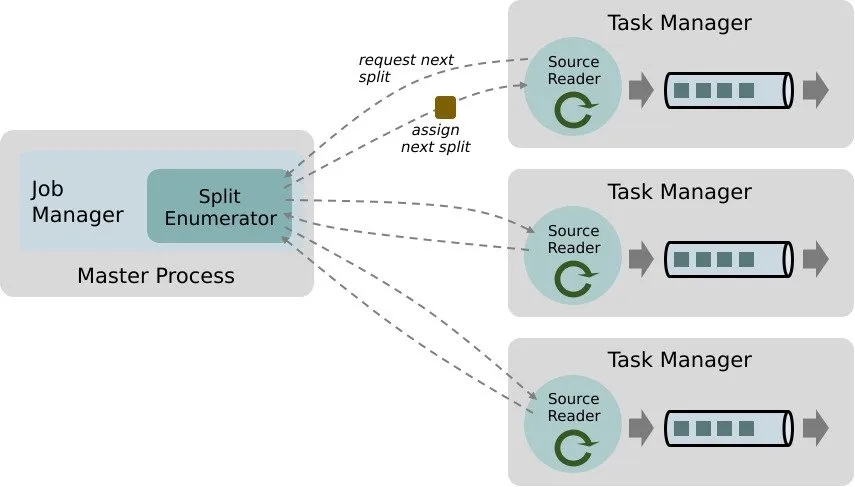
Apache Flink Source Connector for Delta Lake tables
By Krzysztof Chmielewski , Scott Sandre , Denny Lee
We are excited to announce the release of Delta Connectors 0.5.0, which introduces the new Flink/Delta Source Connector on Apache Flink™ 1.13 that can read directly from Delta tables using Flink’s DataStream API.
Delta 2.0 - The Foundation of your Data Lakehouse is Open
By Tathagata Das , Denny Lee
We are happy to announce the release of the Delta Lake 2.0 on Apache Spark™ 3.2! The significance of Delta Lake 2.0 is not just a number - though it is timed quite nicely with Delta Lake’s 3rd birthday. It reiterates our collective commitment to the open-sourcing of Delta Lake, as announced by Michael Armbrust’s Day 1 keynote at Data + AI Summit 2022.
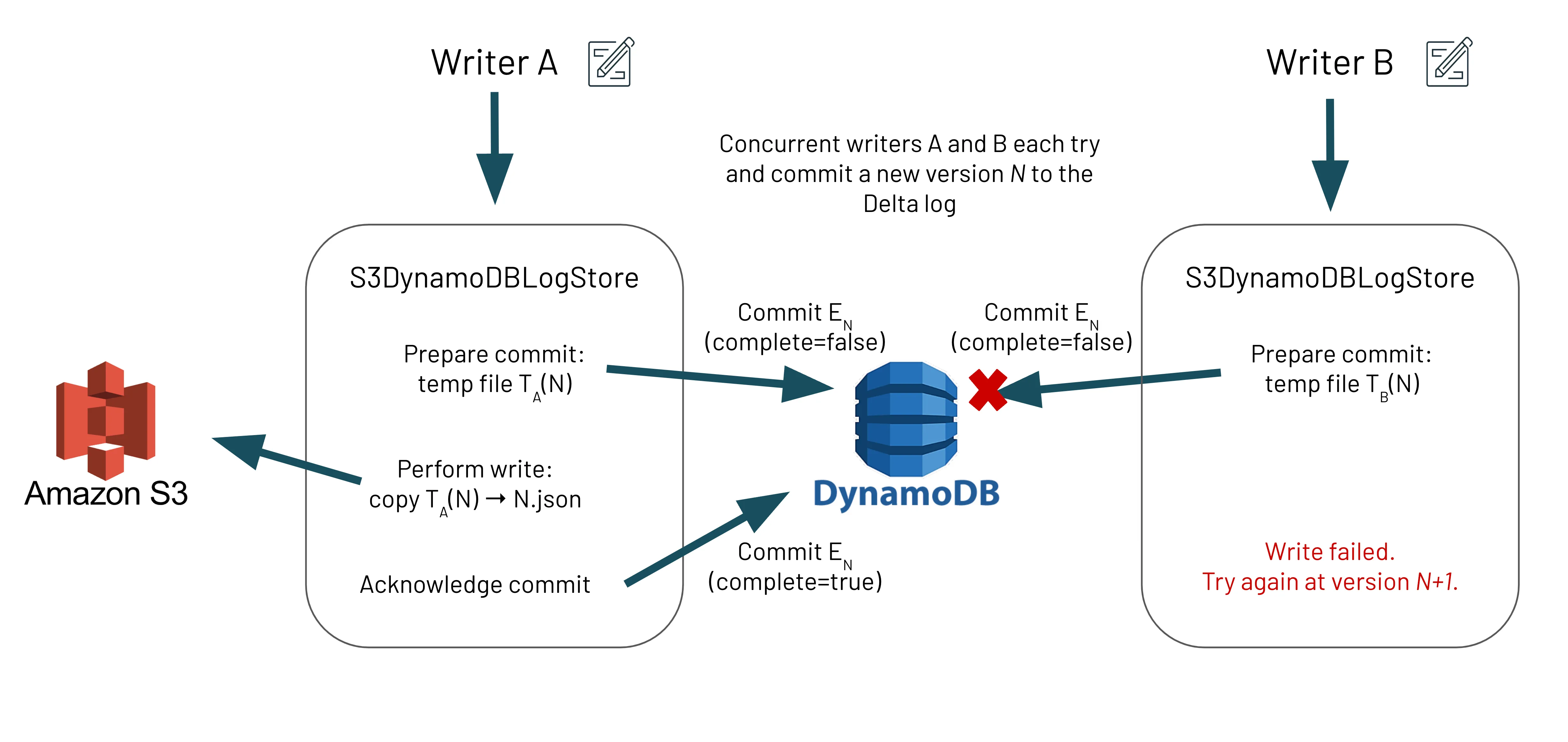
Multi-cluster writes to Delta Lake Storage in S3
By Scott Sandre , Denny Lee , Mariusz Kryński
While Delta Lake has supported concurrent reads from multiple clusters since its inception, there were limitations for multi-cluster writes specifically to Amazon S3. Note, this was not a limitation for Azure ADLSgen2 nor Google GCS, as S3 currently lacks “put-If-Absent” consistency guarantees. Thus, to guarantee ACID transactions on S3, one would need to have concurrent writes originating from the same Apache Spark™ driver. This was one of the most requested issues by the community and we are excited to announce that Delta Lake 1.2 (release notes, blog) now supports writing data from multiple clusters to S3 while maintaining the transactionality of the writes.
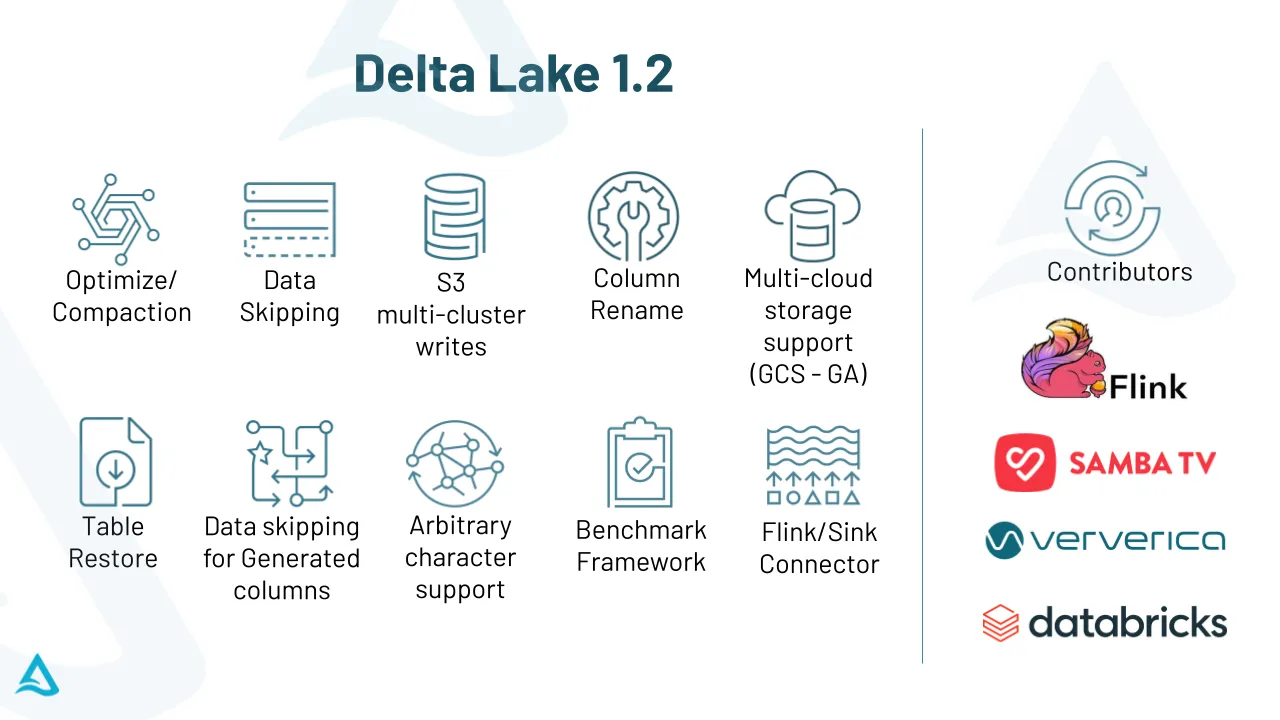
Delta Lake 1.2 - More Speed, Efficiency and Extensibility Than Ever
By Venki Korukanti , Scott Sandre , Tathagata Das , Allison Portis , Denny Lee , Vini Jaiswal
Introducing performance optimizations that will supercharge your data pipelines at any scale.
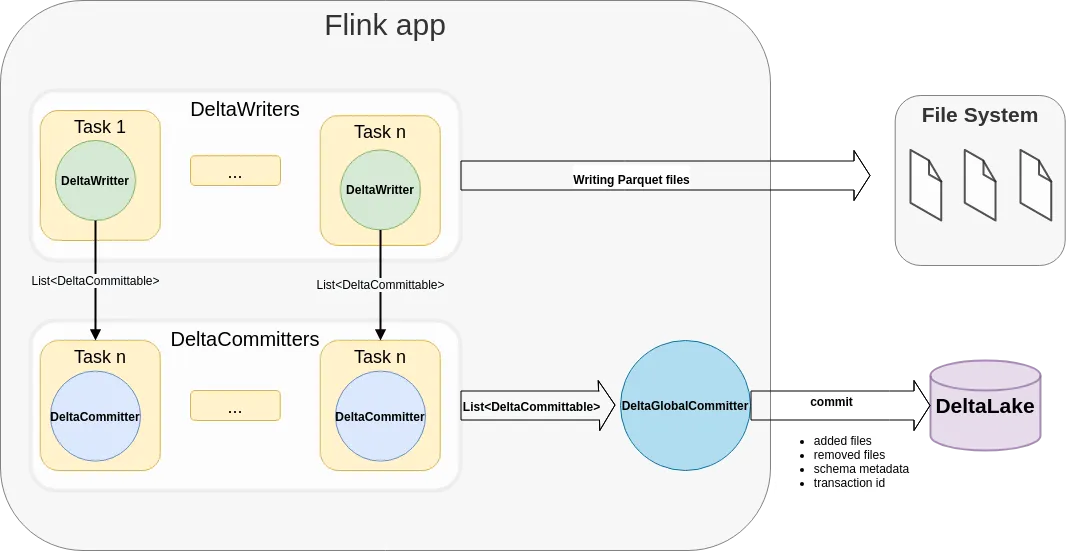
Writing to Delta Lake from Apache Flink
By Fabian Paul , Pawel Kubit , Scott Sandre , Tathagata Das , Denny Lee
Learn more about how you can write from Apache Flink to Delta Lake about the latest release of the open-source project Delta Sharing and how it enables sharing on Google Cloud Storage, among other enhancements.
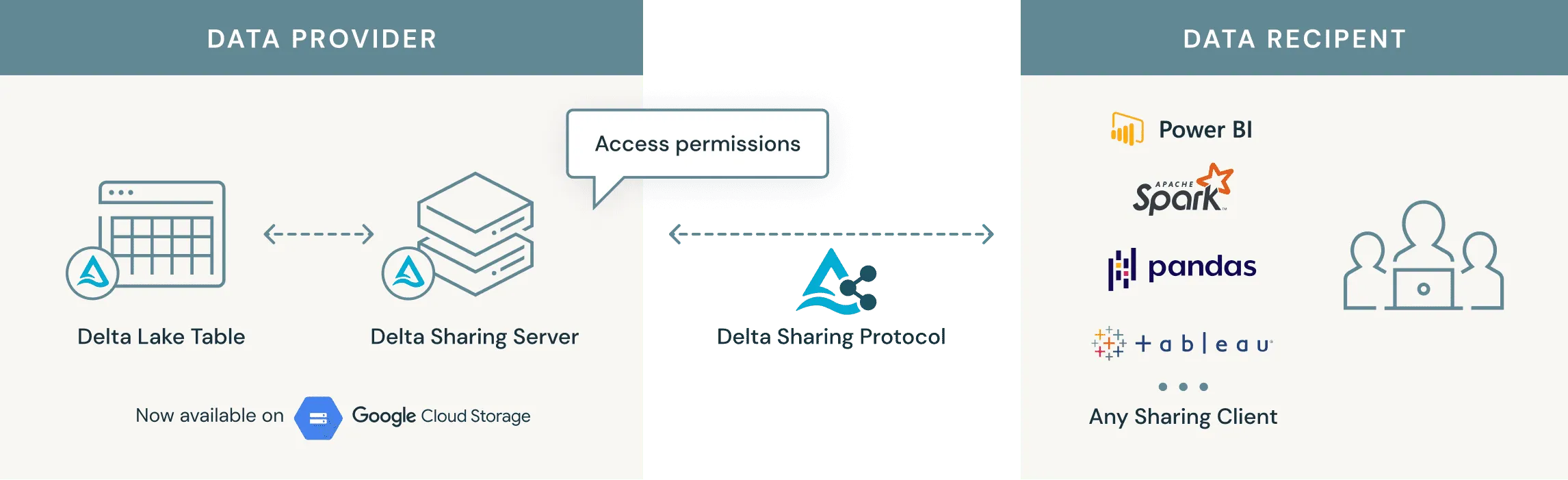
Extending Delta Sharing to Google Cloud Storage
By Will Girten , Shixiong Zhu
Learn more about the latest release of the open-source project Delta Sharing and how it enables sharing on Google Cloud Storage, among other enhancements.
Delta Connectors 0.3.0 Released
We are excited to announce the release of Delta Connectors 0.3.0.